| EXCALIBUR Adaptive Constraint-Based Agents in Artificial Environments |
| [ENHANCEMENT] | [Durations] [Optimization] [Dynamics] [Other Extensions] |
| [ Please note: The project has been discontinued as of May 31, 2005 and is superseded by the projects of the ii Labs. There won't be further updates to these pages. ] |
(Related publication: [PUBLink])
So far, only satisfaction goals have been considered. However, the construction of a plan - using domain knowledge - could actually be accomplished in linear time by adding the necessary actions for one package after the other. Even using a very unsophisticated approach, 12 actions at the most would be necessary per package: a truck is driven to the package's location, the package is loaded on the truck, the truck is driven to the airport, the package is unloaded, an airplane is flown to the airport, the package is loaded on the airplane, the airplane is flown to the destination city, the package is unloaded, a truck is driven to the airport, the package is loaded on the truck, the truck is driven to the package's destination, and the package is unloaded.
If a minimization of the total delivery time (i.e., minimizing the maximal completion time of the single deliveries) is desired, a goal function can be incorporated into the SRC that returns the duration from 0 to the Begin of the Precondition Tasks of the SGoals's Task Constraint. An improvement heuristic for this goal function can be implemented very simply: it shifts the Precondition Tasks in the direction of the current time until the first time point is reached at which the SRC's inconsistency increases.
The question now is the balance between satisfaction and optimization (see also Section [Goal Optimization]). Here, the same hierarchical approach as in the Orc Quest example is taken, i.e., optimization of the goal function is only started if the cost function reaches 0.
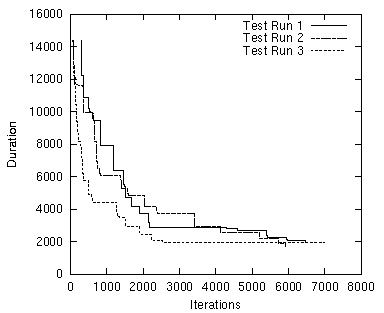
The initial time point for the Begin variables of the Precondition Tasks of the SGoals's Task Constraint is not really important as long as it allows enough time for a consistent solution. For the following experiments, it is set to NumberOfPackages × MaximallyNecessaryActionsPerPackage × MaximalActionLength, i.e., for the 6-1 modifications, 6 × 12 × 200 = 14400. The figure below presents three sample test runs for Problem 6-1a, in which the development of the duration of consistent solutions can be seen. The runtime was set to 10,000 iterations for these test runs. The dips indicate an application of the SRC's goal heuristic, while the plateaus indicate a search for a new consistent solution.
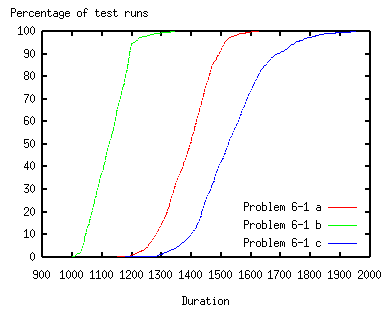
For Problems 6-1a, 6-1b and 6-1c, the figure below shows how many test runs found a certain duration for a runtime of 100,000 iterations. The shortest durations found are 1,150 for 6-1a, 1,004 for 6-1b and 1,177 6-1c.
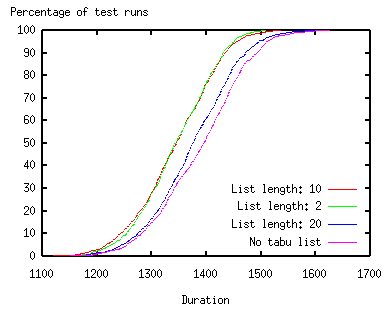
Again, the use of tabu lists can yield a significant improvement (the figure below shows the durations found for Problem 6-1a). However, in contrast to the previous application of tabu lists, the number of possible actions is restricted here because of the optimization performed. This causes that tabu lists of a longer length do not improve the results anymore - there is even a deterioration in the results in contrast to shorter lists.
| [ENHANCEMENT] | [Durations] [Optimization] [Dynamics] [Other Extensions] |
For questions, comments or suggestions, please contact us.
Last update:
May 20, 2001 by Alexander Nareyek